
В этой статье мы узнаем, как настроить Prometheus и Alert Manager для кластера Kubernetes с пользовательскими оповещениями | How to Set Up Prometheus and AlertManager in Kubernetes with Custom Alerts. Эффективный мониторинг является неотъемлемой частью управления кластерами Kubernetes. Prometheus в сочетании с AlertManager предлагает надежное решение для отслеживания состояния и производительности ваших приложений. Мы проведем вас через пошаговый процесс настройки Prometheus и AlertManager в Kubernetes, включая конфигурирование пользовательских оповещений.
Предварительные условия
- Учетная запись AWS с инстансом EC2 Ubuntu 24.04 LTS.
- Minikube и kubectl, Helm установлен
- Базовые знания о Kubernetes
Шаг #1:Настройка инстанса Ubuntu EC2
Обновите список пакетов.
sudo apt update
Устанавливает такие необходимые инструменты, как curl, wget и apt-transport-https.
sudo apt install curl wget apt-transport-https -y
Устанавливает Docker, контейнерную среду выполнения, которая будет использоваться в качестве драйвера ВМ для Minikube.
sudo apt install docker.io -y
Добавьте текущего пользователя в группу Docker, что позволит ему выполнять команды Docker без sudo.
sudo usermod -aG docker $USER
Настройте разрешения для сокета Docker, чтобы упростить взаимодействие с демоном Docker.
sudo chmod 666 /var/run/docker.sock
Проверяет, поддерживает ли система виртуализацию.
egrep -q 'vmx|svm' /proc/cpuinfo && echo yes || echo no
Установите KVM и сопутствующие инструменты.
sudo apt install qemu-kvm libvirt-clients libvirt-daemon-system bridge-utils virtinst libvirt-daemon
Добавление пользователя в группы виртуализации.
sudo adduser $USER libvirt
sudo adduser $USER libvirt-qemu
Перезагрузка группы.
newgrp libvirt
newgrp libvirt-qemu
Шаг #2:Установите Minikube и kubectl
Загрузите последнюю версию бинарного файла Minikube.
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
Установите его в /usr/local/bin, сделав его доступным для всей системы.
sudo install minikube-linux-amd64 /usr/local/bin/minikube
Использование версия minikube команда для подтверждения установки.
minikube version
Загрузите последнюю версию kubectl (Kubernetes CLI).
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
Сделайте двоичный файл kubectl исполняемым.
chmod +x ./kubectl
переместить в /usr/local/bin
sudo mv kubectl /usr/local/bin/
Использование версия kubectl команда для проверки установки.
kubectl version --client --output=yaml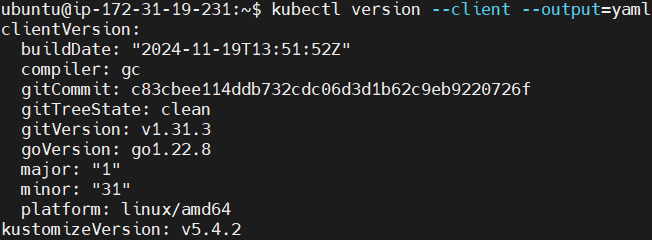
Шаг № 3:Запуск Minikube
Запустите Minikube с Docker в качестве драйвера.
minikube start --vm-driver docker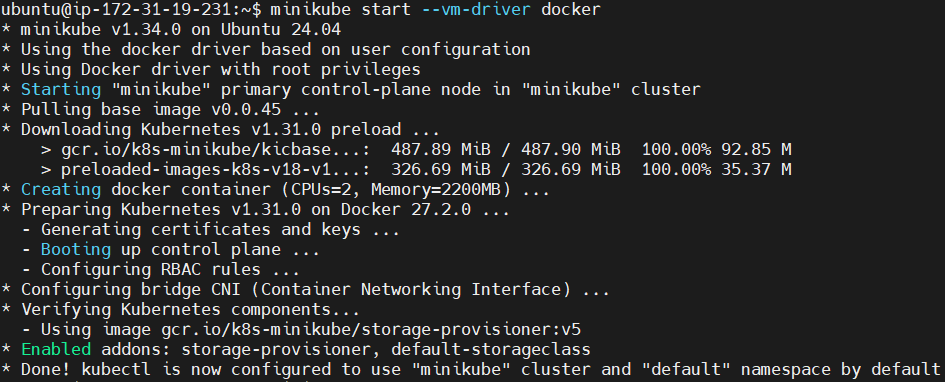
Чтобы проверить состояние Minikube, выполните следующую команду.
minikube status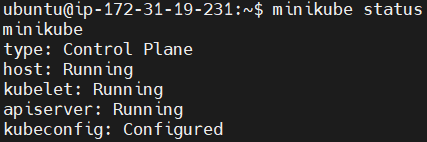
Шаг #4:Установите Helm
Загрузите helm, менеджер пакетов для Kubernetes.
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
Измените его разрешения.
chmod 700 get_helm.sh
Установите шлем.
./get_helm.sh
Проверьте его версию, чтобы подтвердить установку.
helm version
Добавьте репозиторий Prometheus Helm Chart Repository.
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
обновите репозитории Helm для получения последних графиков.
helm repo update
Шаг #5:Настройка Prometheus, Alertmanager и Grafana на кластере Kubernetes
Создайте файл custom-values.yaml для настройки сервисов Prometheus и Grafana в качестве NodePort
nano custom-values.yaml
Добавьте следующую конфигурацию.
prometheus:
service:
type: NodePort
grafana:
service:
type: NodePort
alertmanager:
service:
type: NodePort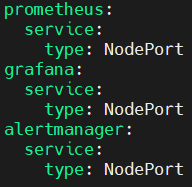
Разверните стек Prometheus, Alertmanager и Grafana.
helm upgrade --install kube-prometheus-stack prometheus-community/kube-prometheus-stack -f custom-values.yaml
Эта команда развернет Prometheus, Alertmanager и Grafana на вашем кластере с сервисами, открытыми как NodePort.
Шаг #6:Доступ к Prometheus, Alertmanager и Grafana
Перечислите сервисы для получения информации о NodePort.
kubectl get services
Перенаправьте службу Prometheus на порт 9090.
kubectl port-forward --address 0.0.0.0 svc/kube-prometheus-stack-prometheus 9090:9090
Получите доступ к пользовательскому интерфейсу Prometheus через веб-браузер, используя http://<EC2-Public-IP>:9090.
Откройте вкладку duplicate и переадресуйте службу Alertmanager на порт 9093.
kubectl port-forward --address 0.0.0.0 svc/kube-prometheus-stack-alertmanager 9093:9093
Получите доступ к пользовательскому интерфейсу Alertmanager через веб-браузер, используя http://<EC2-Public-IP>:9093.
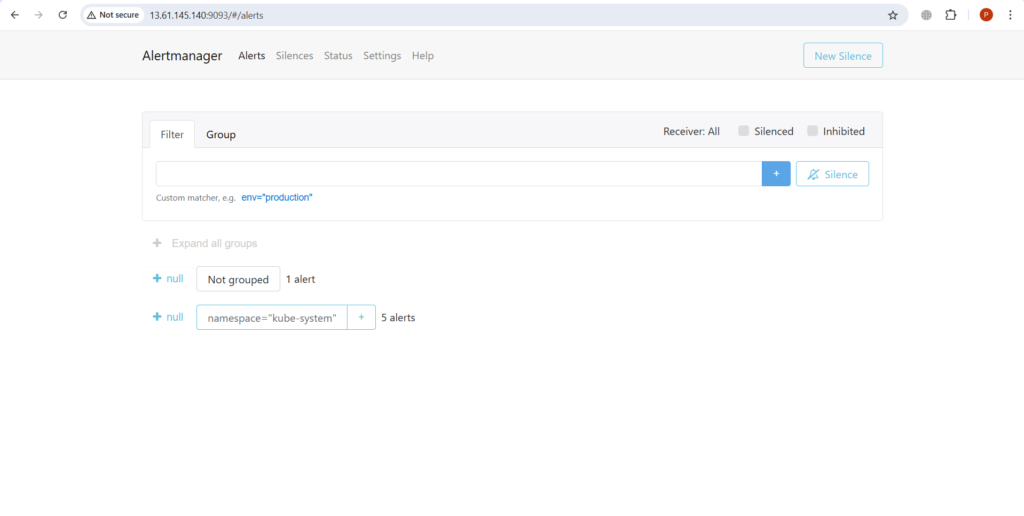
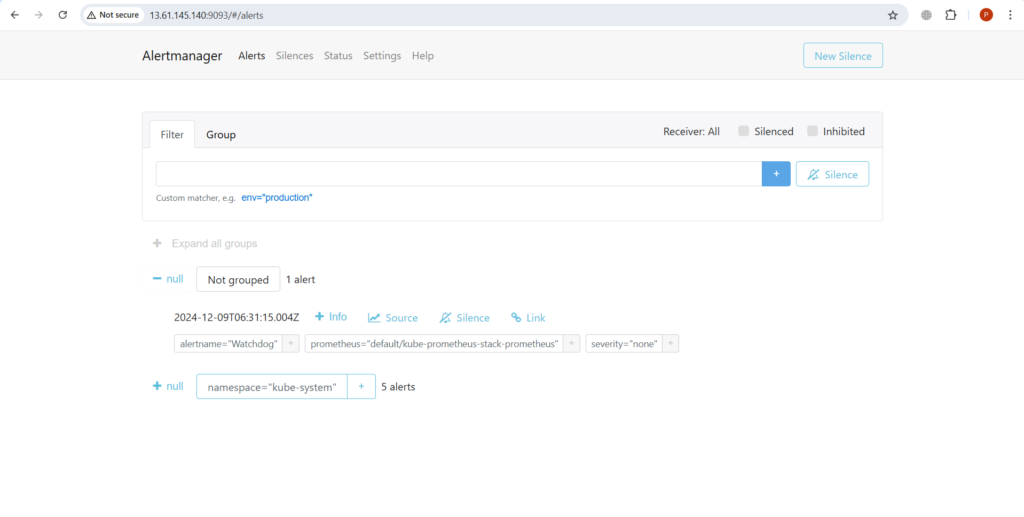
Чтобы получить доступ к оповещениям alertmanager, нажмите на оповещения в Prometheus UI, чтобы увидеть их.
Здесь вы можете увидеть оповещения, которые находятся в состоянии запуска, и вы также можете увидеть их в пользовательском интерфейсе alertmanager
Откройте вкладку duplicate и переадресуйте службу Grafana на порт 3000.
kubectl port-forward --address 0.0.0.0 svc/kube-prometheus-stack-grafana 3000:80
Доступ к пользовательскому интерфейсу Grafana в веб-браузере с помощью http://<EC2-Public-IP>:3000.
Шаг #7:Настройка пользовательских правил оповещений
Итак, мы рассмотрели оповещения по умолчанию, настроенные в prometheus и alertmanager.
Далее попробуем добавить в них пользовательские правила оповещений для мониторинга нашего кластера kubernetes.
Откройте еще одну дублирующую вкладку. Создайте и определите правила оповещения в custom-alert-rules.yaml файле.
nano custom-alert-rules.yaml 
добавьте в него следующее содержимое.
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
app: kube-prometheus-stack
app.kubernetes.io/instance: kube-prometheus-stack
release: kube-prometheus-stack
name: kube-pod-not-ready
spec:
groups:
- name: my-pod-demo-rules
rules:
- alert: KubernetesPodNotHealthy
expr: sum by (namespace, pod) (kube_pod_status_phase{phase=~"Pending|Unknown|Failed"}) > 0
for: 1m
labels:
severity: critical
annotations:
summary: Kubernetes Pod not healthy (instance {{ $labels.instance }})
description: "Pod {{ $labels.namespace }}/{{ $labels.pod }} has been in a non-running state for longer than 15 minutes.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesDaemonsetRolloutStuck
expr: kube_daemonset_status_number_ready / kube_daemonset_status_desired_number_scheduled * 100 < 100 or kube_daemonset_status_desired_number_scheduled - kube_daemonset_status_current_number_scheduled > 0
for: 10m
labels:
severity: warning
annotations:
summary: Kubernetes DaemonSet rollout stuck (instance {{ $labels.instance }})
description: "Some Pods of DaemonSet {{ $labels.namespace }}/{{ $labels.daemonset }} are not scheduled or not ready\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: ContainerHighCpuUtilization
expr: (sum(rate(container_cpu_usage_seconds_total{container!=""}[5m])) by (pod, container) / sum(container_spec_cpu_quota{container!=""}/container_spec_cpu_period{container!=""}) by (pod, container) * 100) > 80
for: 2m
labels:
severity: warning
annotations:
summary: Container High CPU utilization (instance {{ $labels.instance }})
description: "Container CPU utilization is above 80%\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: ContainerHighMemoryUsage
expr: (sum(container_memory_working_set_bytes{name!=""}) BY (instance, name) / sum(container_spec_memory_limit_bytes > 0) BY (instance, name) * 100) > 80
for: 2m
labels:
severity: warning
annotations:
summary: Container High Memory usage (instance {{ $labels.instance }})
description: "Container Memory usage is above 80%\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesContainerOomKiller
expr: (kube_pod_container_status_restarts_total - kube_pod_container_status_restarts_total offset 10m >= 1) and ignoring (reason) min_over_time(kube_pod_container_status_last_terminated_reason{reason="OOMKilled"}[10m]) == 1
for: 0m
labels:
severity: warning
annotations:
summary: Kubernetes Container oom killer (instance {{ $labels.instance }})
description: "Container {{ $labels.container }} in pod {{ $labels.namespace }}/{{ $labels.pod }} has been OOMKilled {{ $value }} times in the last 10 minutes.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesPodCrashLooping
expr: increase(kube_pod_container_status_restarts_total[1m]) > 3
for: 2m
labels:
severity: warning
annotations:
summary: Kubernetes pod crash looping (instance {{ $labels.instance }})
description: "Pod {{ $labels.namespace }}/{{ $labels.pod }} is crash looping\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"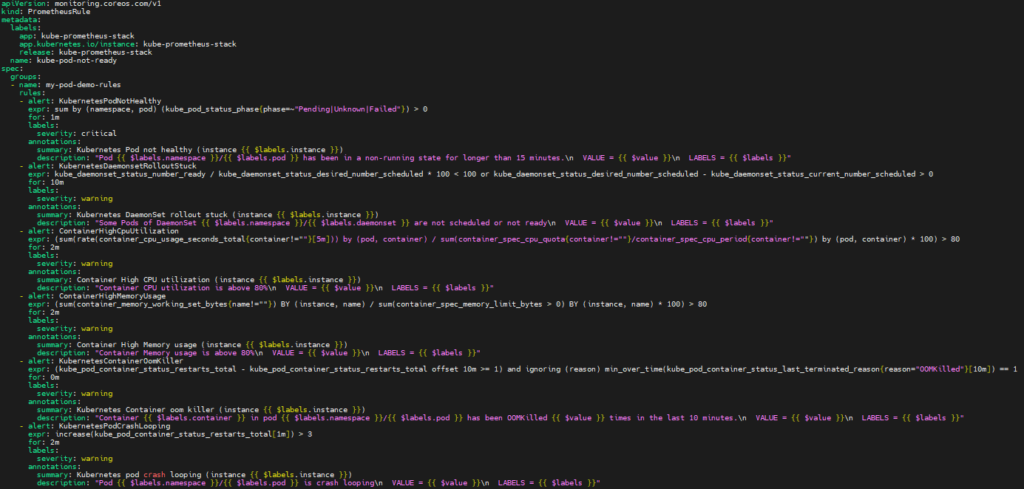
Примените пользовательские правила оповещений к кластеру kubernetes.
kubectl apply -f custom-alert-rules.yaml
затем снова зайдите в пользовательский интерфейс Prometheus, чтобы увидеть пользовательские правила оповещений (обновите страницу).
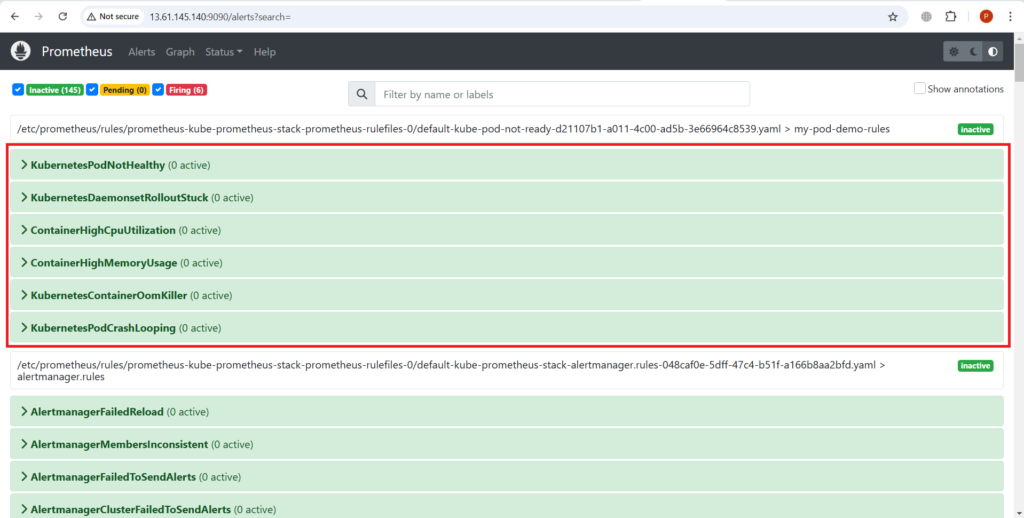
Как видите, мы успешно добавили новые пользовательские правила оповещений в наш alertmanager.
Шаг #8:Развертывание тестового приложения
Теперь, чтобы проверить, как работают наши правила оповещения, создадим приложение с неправильным тегом изображения.
Разверните Nginx pod для тестирования мониторинга и оповещения.
kubectl run nginx-pod --image=nginx:lates3
правильным тегом является latest, но мы написали lates3 для запуска оповещения.
проверьте статус стручка.
kubectl get pods nginx-pod
Как видно, стручок не готов и показывает ошибку ImagePullBackOff.
Теперь это вызовет оповещение, поскольку мы создали пользовательские правила оповещения.
Перейдите в пользовательский интерфейс prometheus и alertmanager, обновите страницу и найдите оповещение, связанное с отказом стручка. Оно должно появиться на пользовательском интерфейсе.
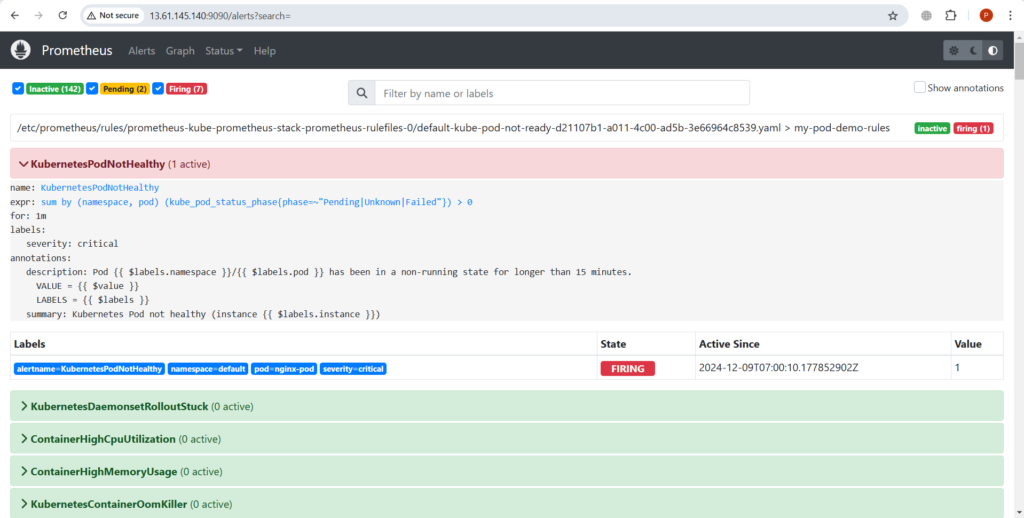
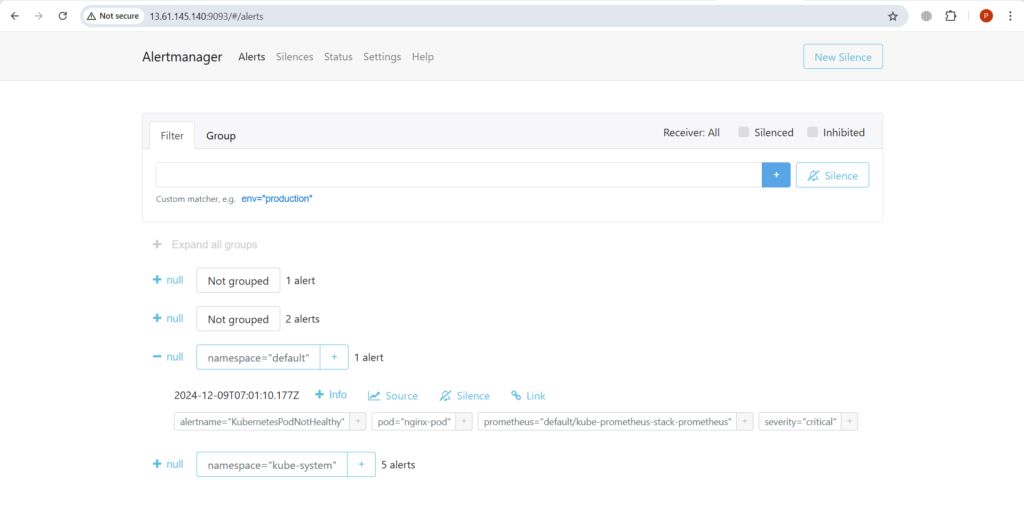
Понимание правил пользовательских оповещений:
Ключевые компоненты правила оповещения:
- Имя: Уникальный идентификатор предупреждения.
- Выражение (expr): Условие PromQL.
- Для: Время сохранения состояния до срабатывания.
- Ярлыки: Метаданные для категоризации оповещений (например,
severity). - Аннотации: Динамическая информация, помогающая диагностировать проблему.
Заключение:
В заключение, сегодня мы рассмотрели, как настроить Prometheus и AlertManager в Kubernetes с пользовательскими оповещениями. Развернув Prometheus и AlertManager, вы сможете получить надежную систему мониторинга кластеров и приложений Kubernetes. Пользовательские оповещения позволяют проактивно реагировать на потенциальные проблемы, повышая надежность и производительность. Интеграция Grafana позволяет визуализировать метрики и оповещения для получения действенных выводов. Расширьте свою настройку, добавив дополнительные пользовательские правила и панели мониторинга для удовлетворения ваших операционных потребностей.